大致先了解 MLP 的原理,因為是學習階段,我的見解錯的機率很高,請勿服毒 ,資料很雜亂,請看看就好..
https://colab.research.google.com/github/lmoroney/mlday-tokyo/blob/master/Lab2-Computer-Vision.ipynb
因為上個範例已經知道是輸入跟結果,所以圖片辨識先不管其他因素,就是輸入圖片的像素跟輸出的對應
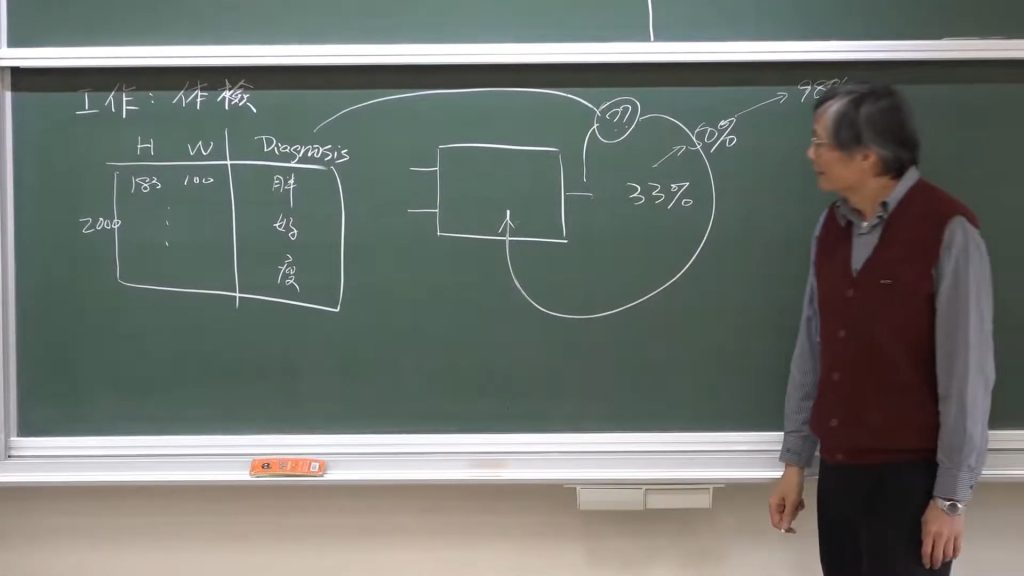
如果已經有 2000 筆存在的資料,可以藉由輸入 身高、體重、預期的結果丟給系統,進行訓練,然後再根據訓練的結果,比對現行的資料看是否正確,再進行第二次的訓練,讓他的準確度如 33% > 50% 到 例如預期的 98%
類似的原理到圖片上 :
- 把圖片展開成像素與物品標籤的對應,讓 AI 訓練
- 再提供他沒看過的圖片,確認他是否學習成功。

看一下別人寫的範例 :
https://www.codeproject.com/Articles/5286497/Starting-with-Keras-NET-in-Csharp-Train-Your-First
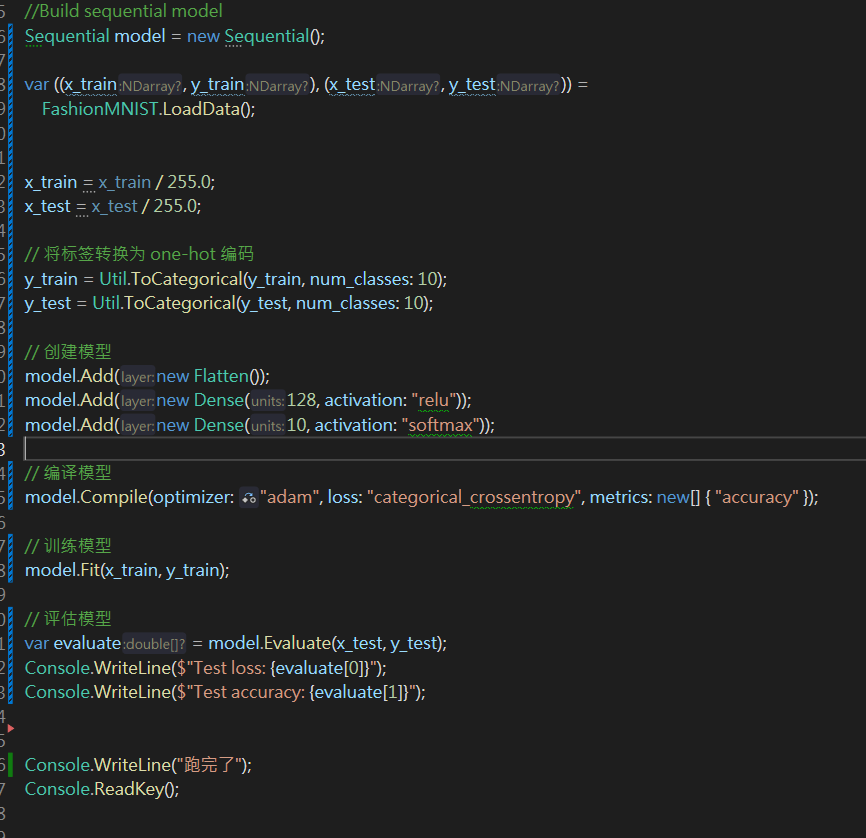
model.Add(new Dense(128, activation: "relu"));
model.Add(new Dense(10, activation: "softmax"));由於運行失敗,直接請 ChatGpt 寫一個 :
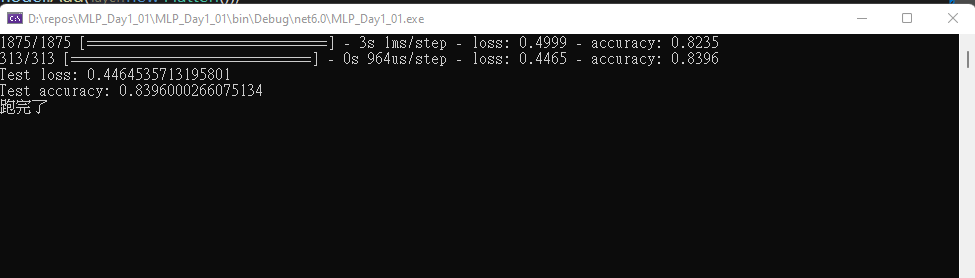
程式碼還無法理解,先記錄一下執行步驟 :